授課教授:交通大學 交通運輸研究所 陳穆臻 教授
參考書籍:Introduction to Data Mining, Tan, P. T., Steinbach, M., Kumar,. Vipin
1. ANN(Artificial Neural Networks)類神經網路
2. Ensemble Methods 群體學習法
3. AdaBoost
4. 課後作業
1. ANN(Artificial Neural Networks)類神經網路
上課老師已經先說明ANN等演算法會在下學期的多變量分析課才會在教。
這裡僅做個大概介紹
類神經網路,是利用模擬人類神經傳導的方式所建構的分類或預測方法
詳細介紹可以參考:WIKI 類神經網路
這是人類神經

簡單由下圖介紹
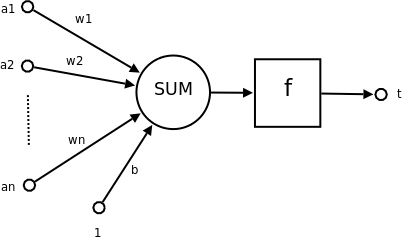
而每個神經都有一個突觸w(很像觸手的東東),因為粗細不同所以代表權重不同
最後集中後,在到一個閥(也就是觸動開關 f)
最後產生t這個結果
有些數學式會這樣表示:

如果 t 只有 0 跟 1 兩個分類的話
當所有神經元的加總 比 閥值 f 來的小的話,t即為 0
反之,若神經元加總 比 閥值 f 來得大的話,t即為 1
2. Ensemble Methods 群體學習法
群體學習法(或稱作全體學習法),其建構的基礎是從「訓練資料(Training Data)」來的
在預測未知的資料前,先分類多組的資料集,接著建立多組的分類模型
然後丟入未知資料,最後從多個模型中找出最佳解(一般採用多數決定)。
原始資料 > 拆成很多組 > 變出很多模型 > 最後推估結果

為什麼要這樣做呢?答案很簡單
假設今天我們做了25個分類模型,每個模型的錯誤率是35%
這樣透過25個模型所跑出來的資料,他的錯誤率就會只剩下 6%

(25個分類模型至少要13個以上決定才行)
1. Bagging 也就是抽後放回,今天假設有10筆資料的話,可以抽出下面結果

2. Boosting ,不只抽後放回,還會對每筆資料給予權重值,來提高抽樣機率
第一輪抽樣,每個資料的機率是都一樣的
第二輪開始,被分類錯誤的資料,會給予較高的權重,這樣就容易被抽出來

如圖,因為第四筆資料常常被分類錯誤,所以要經常抽出來訓練
3. AdaBoost
接著,介紹一個Boost的分類演算法,叫做「AdaBoost」
假設我們有T個分類模型,分別為 C1、C2、C3、.....、CT
其每個分類模型錯誤率的計算方式為


因此,每一輪後權重的計算公式為
第 J+1 回的新權重,要從第 J 回的結果去更新,Z只是一個為了讓權重加總=1的值

接著,AdaBoost的重點就是,當錯誤率高達50%以上的話,權重將打回 1/n
並且重新做一次抽樣。
最後,分類的結果就是「多數決」,哪個結果分類器決定的多,就已哪個結果為主
